2020/06/18 - [Computer Vision/Classification] - 개와 고양이 분류하기 - 0
2020/06/18 - [Computer Vision/Classification] - 개와 고양이 분류하기 - 1
이전 포스팅에 앞서 필자는 kaggle의 데이터셋을 믿을 수 없기에..
trash데이터를 먼저 처리하는 작업을 해야한다.
일일이 데이터를 모두 확인하기에는 매우 귀찮은 일이기도 하고, 우리는 딥러닝을 공부하는 사람이기에
딥러닝으로 이를 해결해보고자 한다.
가장먼저 해야할 일은 CNN 기본 모델을 이용하여 train데이터를 모두 검수시키는 일이다.
그럼 바로, CNN모델을 이용하여 Dogs vs Cats의 데이터셋만 훈련시켜 모델을 생성해보자.
모델의 목표는 정확도 70~80%를 목표로 훈련시킨 다음, 모든 데이터 셋의 train 데이터를 모두 predict하는 것이다.
trash 데이터의 기준은 두가지로 세워서 추출하는 것이다.
1. 분류가 잘되었지만 정확도가 90% 이하인 데이터
2. 분류가 제대로 안된 데이터
그럼 바로 우리의 Stupid 모델을 설계해보자.
Stupid모델을 생성할 때, 중요한 점은 train데이터를 분류하는게 목적이기 때문에
당연히 overfitting 이전의 가중치를 이용해야 한다는 것이다.
1. 라이브러리 import
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
from PIL import Image , ImageDraw
from sklearn.preprocessing import *
import time
import ast
import os
import keras
import tensorflow as tf
from keras import models, layers
from keras import Input
from keras.models import Model, load_model
from keras.preprocessing.image import ImageDataGenerator
from keras import optimizers, initializers, regularizers, metrics
from keras.callbacks import ModelCheckpoint, EarlyStopping
from keras.layers import BatchNormalization, Conv2D, Activation , AveragePooling2D , Input ,Dropout
from keras.layers import Dense, GlobalAveragePooling2D, MaxPooling2D, ZeroPadding2D, Add, Flatten
from keras.models import Sequential
from keras.metrics import top_k_categorical_accuracy
from keras.callbacks import ModelCheckpoint, ReduceLROnPlateau, EarlyStopping
from keras.applications import ResNet50, vgg19,mobilenet_v2,InceptionV3 , InceptionResNetV2,DenseNet169
from tqdm import tqdm
import cv2뭔가 엄청나게 많이 import했지만, 사실 필요한것만 있진 않고.. 귀찮음에 이전 코드에서 복붙 했다.
(이 글을 읽고 해보려는 사람이 있다면, 자신이 이용하는 것만 import 하길 바란다..)
2. 이미지 파일 목록 만들기
path = 'dogvscat/train/'
filename = os.listdir(path)
datalist = pd.DataFrame(data=[],columns=['label','img'])
label = []
img = []
for file in tqdm(filename) :
label.append(file.split('.')[0])
img.append(file)
datalist['label'] = label
datalist['img'] = img
datalist.head()| 100%|██████████| 25000/25000 [00:29<00:00, 852.09it/s] |
| label | img |
| cat | cat.5425.jpg |
| cat | cat.11750.jpg |
| cat | cat.3689.jpg |
| cat | cat.6375.jpg |
| dog | dog.11201.jpg |
3. 데이터 갯수 확인하기
catnum = 0
dognum = 0
for i in datalist['label'] :
if i == 'cat' :
catnum += 1
if i == 'dog' :
dognum += 1
plt.bar([1,2],[catnum,dognum],tick_label=['cat','dog'])
plt.legend()
4. 이미지 크기 변경 및 데이터 input 생성
def preprocessing(path) :
X= []
Y= []
class_label = []
class_num = 2
for num in tqdm(range(len(datalist['img']))) :
img = cv2.imread(path+datalist['img'][num])
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
img = cv2.resize(img,(160,160))
if datalist['label'][num] == 'cat' :
X.append(img)
Y.append(0)
else :
X.append(img)
Y.append(1)
tmpx = np.array(X)
Y = np.array([[i] for i in Y])
enc = OneHotEncoder(categories='auto')
enc.fit(Y)
tmpy = enc.transform(Y).toarray()
del X
del Y #RAM메모리 절약을 위해 사용하지 않는 변수 삭제
return tmpx , tmpy , class_label , class_num
tmpx , tmpy , class_label , class_num = preprocessing(path) #파일이름이 담긴 배열
print(tmpx.shape, tmpy.shape)| 100%|██████████| 25000/25000 [02:41<00:00, 154.36it/s] (25000, 160, 160, 3) (25000, 2) |
5. 이미지 확인
plt.imshow(tmpx[40])
tmpy[40]
6. Train set , Validation set 분리
from sklearn.model_selection import train_test_split
X_train, X_val, Y_train, Y_val = train_test_split(tmpx,tmpy, test_size = 0.2,random_state = 1)
del tmpx
del tmpy #RAM메모리 절약을 위해 사용하지 않는 변수 삭제
print(X_train.shape,X_val.shape,Y_train.shape,Y_val.shape)| (20000, 160, 160, 3) (5000, 160, 160, 3) (20000, 2) (5000, 2) |
7. 데이터 Generating
nb_train_samples = len(X_train)
nb_validation_samples = len(X_val)
batch_size = 16
train_datagen = ImageDataGenerator(
rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
val_datagen = ImageDataGenerator(
rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
train_generator = train_datagen.flow(np.array(X_train), Y_train, batch_size=batch_size)
validation_generator = val_datagen.flow(np.array(X_val), Y_val, batch_size=batch_size)
8. CNN 모델 설계
model = Sequential()
model.add(Conv2D(8, (3, 3), activation='relu', input_shape=(160, 160, 3)))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(16, (3, 3), activation='relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(2, activation='sigmoid')) # 2 because we have cat and dog classes
model.summary()
9. 모델 훈련 진행
모델은 overfitting이 됬을 때 부터 필요없어지므로 30epoch만 빠르게 훈련 시켰다.
learning_rate = 0.0001
reduceLROnPlat = ReduceLROnPlateau(monitor='val_loss', factor=0.5, patience=3,
verbose=1, mode='auto', min_delta=0.005, cooldown=5, min_lr=learning_rate)
modelCheckpoint = ModelCheckpoint('stupid_classifier.h5', monitor='val_loss', verbose=1, save_best_only=True)
callbacks = [reduceLROnPlat, modelCheckpoint]
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
history = model.fit_generator(
train_generator,
steps_per_epoch=nb_train_samples // batch_size,
epochs=30,
validation_data=validation_generator,
validation_steps=nb_validation_samples // batch_size,
callbacks=callbacks
)Epoch 30/30 1250/1250 [==============================] - 76s 61ms/step - loss: 0.3368 - accuracy: 0.8517 - val_loss: 0.6398 - val_accuracy: 0.8064
최종 Acc가 80%의 정확도를 가진 모델이 만들어 졌지만,
우리는 overfitting이 되기 전 가장 정확한 모델을 사용하기 위해 그래프를 그려 history를 확인해 보았다.
10. 훈련 진행상황 확인
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1,len(acc) + 1 )
plt.plot(epochs, acc, 'r' , label = 'Training Accuracy')
plt.plot(epochs, val_acc, 'b' , label = 'Validation Accuracy')
plt.title('Training and Validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'r' , label = 'Training Loss')
plt.plot(epochs, val_loss, 'b' , label = 'Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
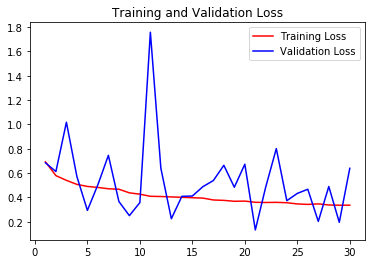
훈련이 진행된 그래프를 보면 epoch가 적어서 그런지 overfitting이 이루어진 시점을 정확하게 판단하기 어렵다.
굳이 판단하자면 validation acc가 상대적으로 train보다 낮아지는 25epoch 시점부터라고 할 수 있다.
우리는 훈련 과정중 loss 값이 가장 낮게 나왔던 21epoch의 모델을 사용하는것이 가장 좋겠다.
Epoch 21/30 1250/1250 [==============================] - 75s 60ms/step - loss: 0.3607 - accuracy: 0.8411 - val_loss: 0.1336 - val_accuracy: 0.8244
21 epoch의 acc는 약 82% , loss값은 약 0.13 정도 이므로, 우리가 목표했던 Stupid모델에 적합한 모델이다.
그럼 이제 모든 데이터를 검수..하는건 다음 포스팅에서 ..
'Computer Vision > Classification' 카테고리의 다른 글
| imgaug 패키지를 이용하여 데이터 증강하기 (0) | 2020.10.13 |
|---|---|
| 개와 고양이 분류하기 - 1 (0) | 2020.06.18 |
| 개와 고양이 분류하기 - 0 (0) | 2020.06.18 |


