SOTA를 확인하다 읽었던 CSPNet에 대해 작성해보려고 한다.
논문의 제목은 CSPNET: A NEW BACKBONE THAT CAN ENHANCE LEARNING CAPABILITY OF CNN 으로
직역 하자면 이 포스팅의 제목과 같이 CNN의 학습능력을 향상 시킬 수 있는 새로운 백본 이라고 한다.
엄청나게 자신감 있는 논문 제목이라고 느껴진다.
그럼 논문에 내용에 대해 정리해보겠다.
요약
요약의 첫 시작 부분에는 신경망은 컴퓨터 비전 영역에서 놀라운 발전을 이뤘지만 이 고급 기술들은 값싼 장치를 가진 사람들에게 이용되지 못하고 있다고 소개하고 있다. (실제로 GPU없는 환경에서 딥러닝하기란 쉽지 않다.)
컴퓨팅 파워가 낮은 환경이 감당하기 힘든 연산량을 완화시킬 수 있는 모델이 Cross Stage Partial Network(CSPNet) 이라고 소개하고 있다. 그리고 간단하게 네트워크의 소개 하고 있는데, 연상량이 많아지는 이유는 네트워크가 optimaization하는 과정에서 gradients의 정보 중복으로 인한 것이라고 말하며, 제안하는 네트워크가 gradients의 다양성을 시작단과 끝 단의 통합 과정을 통해 respect 한다고 한다.(존중..? 존경? 한글로 하면 의미가 어색해진다.)
마지막으로 CSPNet은 ImageNet, MS COCO 같은 컴퓨터 비전의 대표적인 데이터에서 성능을 크게 향상시켰다고 한다.
소개
소개에서는 보통의 논문들이 그렇듯 일반적인 상황을 이야기한다. 대충 읽어보자면 이렇다. 뉴럴 네트워크는 깊어지고 넓어질수록 그 효과가 강해지는 것을 우리가 보아왔다. 그러나 architecture(구조)의 확장은 뉴럴 네트워크의 연산량이 많아지게하고, 그것은 값싼 장치를 사용하는 사람들에게는 object detection같은 작업이 너무나도 무겁다는 것이다.
real-world에 사용되는 어플리케이션들은 사용하는 장치가 작고 짧은 inference time이 필요하므로 경량화 작업이 주목받고 있다. Depth-wise convolution 같은 기술은 모바일 장치에서 적용할 수 있게 설계되었다곤 하지만, IC디자인이나 ASIC(어플리케이션 직접회로..? 잘모르겠다.)에서 이용하기에는 너무 무겁다는 것이다.(실제로 MobileNet의 가장 큰 특징은 Depth-wise convolution이라고 볼 수 있다.)
SOTA에 올라와 있는 ResNet, ResNeXt, DenseNet 같은 모델들을 CPU나 mobile GPU(jetson 같은) 환경에서 성능 저하 없이 이용할 수 있게 개발이 진행 되었다고 한다.
여기까지만 읽어도 논문의 방향성과 연구자의 추구하는바를 전부 알 수 있다. 이제 CSPNet에 대해 자세한 내용들을 읽어 볼 수 있다.
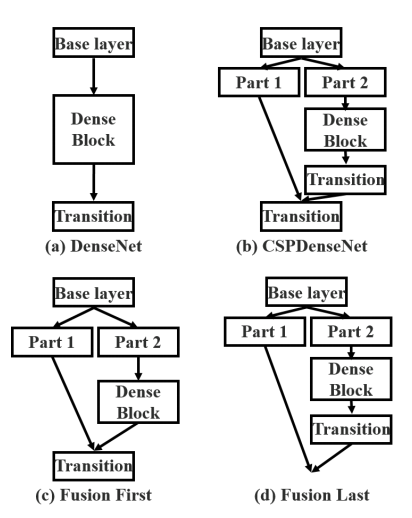
CSPNet의 목적은 점점 많은 gradient combiantion이 만들어지는 동안 연산량을 줄이는 것이라고 한다. 이것은 base layer에서 두개의 파트로 나눈 다음 마지막 cross-stage 계층에서 합침으로써 실현 가능하다라고 저자는 소개한다.
이 작업 (두개의 파트로 나누었다가 합쳐지는 작업)은 gradient가 전파될 때 (CSPNet에 있는) transition step에서 correlation difference가 있는 것을 확인 했다고 한다.
이 작업은 연산량을 크게 줄여주고, 정확도 향상과 inference time을 줄여주었다고 한다. 저자는 이 작업을 소개하기 위해 DenseNet에 CSP기법을 적용시킨 이미지로 소개하고 있다.

앞서 읽었던 아이디어를 사실 생각해보면 당연한 결과이다. base layer를 일부로 쪼개 일부만 convolution연산을 진행한다음 나머지 일부는 그저 합칠 뿐이니, 일부만 이용하기 때문에 convolution 연산의 연산량은 당연히 줄어들 수 밖에 없다. 하지만 이 아이디어를 생각해 내고, 성능 향상까지 있었다고 하니 실로 대단하지 않을 수 없다.
다음은 CSPNet을 이용한 object detection이 3가지 장점을 나타내고 있다고 소개한다.
1. CNN의 학습능력 강화
CSPNet을 이용하면, 정확도를 유지하면서 경량화가 이루어 진다고 한다. 논문에서는 ResNet, ResNeXt, DenseNet에서 10~20% 연산량이 줄었다고 한다.
2. 연산 Bottleneck 삭제
CSPNet을 이용하면, 각 계층의 연산량을 균등하게 분배해서 연산 bottleneck을 없애고 CNN layer의 연산 활용을 업그레이드 시킬 수 있다고 한다. YOLO-v3 모델에서 bottleneck을 80%가량 줄였다고 소개한다.
3. 메모리 cost 감소
CSPNet을 이용하면 메모리 cost를 효과적으로 줄일 수 있다고 하는데 cross-channel pooling이 feature피라미드 작업을 압축 시킬 수 있다고 한다. 이 는 PeleeNet에서 75%의 메모리 사용을 없앴다고 한다.
그 다음은 뭐.. 1080ti나 i9cpu, jetson tx2같은데서 효과를 나타내고 있다는 자랑글이다. 정확한 수치가 궁금하다면 논문을 읽어보길 바란다.
Related work
이 부분에서는 제목 그대로 CSPNet과 관련된 일에 대해 작성이 되어 있다. 하나만 얘기 해보자면, Xie라는 사람은 ResNext에서 cardinality의 중요성을 보여줬고, DenseNet의 경우 재사용을 이용해서 (위 이미지처럼) 파라미터 수를 효과적으로 줄알수 있었고 등등 적혀 있다. 별로 안 궁금하니까 넘어가자.
Method
Cross Stage Partial Network
CSPNet이 어떤 방법으로 설계가 되었는지 에 대한 내용이 써있다. 가장 먼저 DenseNet에 대한 내용이 나오는데 (우리가 익히 알고 있는 DenseNet을 짧게 설명하자면 ResNet은이전 레이어와 현재 레이어를 합산을 통해 ResNet block이 이루어지는 반면, DenseNet은 이름과 같이 연결을 통해 이전 레이어와 현재레이어를 합쳐 Dense block을 이룬다.) 어쨋든, 이 DenseNet의 메커니즘을 식으로 표현하면 이렇다고 한다.
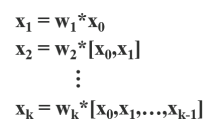
뒤에 있는 이전 layer들의 값이 연결되어 컨볼루션을 통해 가중치와 출력이 만들어지는 구조이다.
역전파를 통해 가중치를 업데이트 할때, 만들어지는 구조는 다음과 같다고 한다.

(여기서 f는 가중치를 업데이트하는 함수, w는 forward pass의 가중치. g는 미분을 통해 얻어지는 기울기를 뜻한다.)
논문의 저자는 이 DensNet의 forward pass와 backward pass의 과정에서 수많은 gradient정보가 재사용 되고 있다고 말하고 있다. 이는 결국 복사된 gradient정보를 반복적으로 학습할 뿐이라고 말하고 있다.
그렇다면 CSPNet은 이를 어떻게 해결했는지 알아보자.
수식으로 논문에 기재되어 있긴 하지만 밑 부분 그림 설명과 함께 보면 더 쉽게 이해할 수 있다.


위 그림과 함께 수식을 보면, base layer의 출력값인 X0' 값이 part1이 되고, X0"가 part2가 된다. 그럼 X0"는 Denseblock을 통과하며 여러 가중치들을 지나 Xk가 되었고 마지막 Trasition layer를 통해 Xt가 된다. 그 후 stage의 마지막 단계에서, part1의 X0'와 part2에서 Denseblock을 지나온 Xt가 만나 Xu가 출력되는 것을 확인 할 수 있다.
역전파 단계 역시 마찬가지로 반대로 이동하며 가중치의 업데이트가 이루어진다.
이러한 구조는 DenseNet의 출력값 연결을 통한 재사용을 유지하면서도, gradient information이 많아지는 것을 방지해준다. 이 것은 계층의 feature fusion으로 인해 이루어질 수 있으며, trasition layer가 그 역할을 한다고 한다.
그래서 이런 것들이 이러쿵 저러쿵 앞에서 했던 이야기들을 실현시킨다~라며 수학적인 설명을 하고 있다. 수학을 못하는 우리는 개념적으로만 이해하고 넘어가는 것으로 하자.
여기까지 논문을 함께 읽었으니 CSPNet의 내용은 다 읽었다고 할 수 있다. 그 뒤에는 자랑글과 함께 object detection에 대한 내용이 나오는데, 그 부분은 밑에서 확인하도록 하고, 여기까지 읽었을 때 느껴지는 것은 기존의 설계된 backbone들의 특성을 그대로 유지하면서도, 아이디어를 통해 성능을 향상 시켰다는 것이다. 이 논문이 대단한데에는 이러한 이유가 있다.
1. 다양한 backbone 모델들을 전혀 건들지 않는다는 점
2. 모든 backbone에 해당 아이디어를 적용시킬 수 있다는 점
3. 그럼에도 유명 모델들이 성능 향상을 이루어 냈다는 점
이렇게 3가지라고 생각이 든다.
Exact Fusion Model
이번에는 Object detection에서 사용되는 detection neck에 대한 이야기를 하고 있다. 이 논문에서 제안하고 있는 detection neck은 EFM기법이라고 소개하는데 EFM에 대해 알아보자.
EFM은 FoV(field of view)를 적절하게 캡처하여 one-stage detector(yolo 나 SSD 같은)를 강화한다고 한다. segmentation 작업에서는.. 안궁금하고, 그러나! 이미지 classify나 detection같은 경우 image-level과 bbox-level labels에서 중요한 정보가 obscure(모호?)해질 수 있다고 말하고 있다. 이러한 image-level에서의 label은 중요한 정보가 모호해 지므로 2-stage detector가 1-stage detector보다 성능이 좋은 이유라고 한다.
(이것에 대해 간단하게 얘기해보면, 2-stage는 localization먼저 하고 해당 box의 이미지 classify를 진행한다.
하지만 1-stage는 localization과 classify를 동시에 진행하기 때문에 전체 image-level에서 critical한 information을 찾기 힘들다라고 할 수 있다.)

해당 이미지에는 3가지 detection neck이 나타나 있다. 피라미드를 이용하는 Yolo의 FPN(feature pyramid Net) (실제로 YOLO의 훈련 과정을 보면 iteration이 3가지의 크기로 진행되는 것을 확인할 수 있다.) ThunderNet(처음 본다..)에서 쓰인다는 GFM(Global fusion Model) 그림을 보면 layer의 feature들이 하나로 합쳐졌다가 세개로 나누어지는 것을 확인할 수 있다. 그리고 EFM(Exact Fusion Model 정확한 퓨젼 모델? ㅋㅋ..) 에서는 두가지의 구조를 섞어서 좀더 balance하게 연산을 할 수 있게 유도하는 것을 알 수 있다.
여기까지가 CSPNet논문의 모든 이론적인 내용이다 그 밑은 실험에 대한 내용인데, 말하자면 자랑글이다. 뭐 어떤 부분에서 성능이 향상되고 메모리 cut down됬고 등등, 실험에 대한 자세한 내용은 논문을 직접 확인하도록 하고 이 포스팅에서는 딥러닝 자랑글에 늘 올라오는 표들을 슥~ 봐보도록 하자.
Experiments




TX2에서 41fps라니.. 대단하다. 이 것으로 논문 리딩에 대한건 마치겠다.
P.S.여기까지 읽어주신 분이 있다면, 굳이 열심히 포스팅글을 남긴 보람이 있을 것같네요. 읽으신 분도 시간 절약이 많이 되었을거라고 생각합니다.
참조 : https://arxiv.org/pdf/1911.11929.pdf
이 포스팅의 정말정말 마지막으로 논문만 읽고 끝내기엔 너무 아쉬우니까 CSP모델의 config파일을 한번 확인해보자. config파일은 yolo framework에 cfg파일인 yolo v4를 확인 해보도록 한다.

가장 쉽게 확인할 수 있는 부분은 CSPDarkNet이 적용된 YOLO v4를 확인해보면, route라는 block을 통해 CSPNet의 특성인 앞단에서 part를 나눈 다음 끝단에서 다시 합치는 것을 확인할 수 있다.
'지식 저장소' 카테고리의 다른 글
| Imbalance Problems in Object Detection : 객체 검출 분야의 불균형 문제 A Review(3) (0) | 2020.11.03 |
|---|---|
| Imbalance Problems in Object Detection : 객체 검출 분야의 불균형 문제 A Review(2) (0) | 2020.11.03 |
| Imbalance Problems in Object Detection : 객체 검출 분야의 불균형 문제 A Review(1) (0) | 2020.11.02 |
| DETR : End-to-end방식의 Transformers를 통한 object detection (2) | 2020.07.07 |
| YOLOv4 : Object detection의 최적의 속도와 정확도 (2) | 2020.06.24 |



