이번 포스팅에서는 YOLOv4의 논문을 리딩해보겠다.
저번 포스팅에서도 최대한 논문의 전반적인 내용을 다루면서 쉽게 설명하려고 노력 했으나.. 여간 어려운 작업이 아닐 수 없다.
각설하고 YOLOv4의 논문을 읽어보자.
요약
논문의 저자는 요약의 첫 시작부분에서 CNN의 정확도를 향상 시킬 수 있는 featrue들이 많다고 말한다.(여러가지 모델들에 대한 내용을 말하는 듯 하다) 대용량의 데이터셋 에서 이런 feature 조합에 대한 테스트와 결과의 이론적인 설명이 필요하다고 하며, 어떤 feature들은 소규모의 데이터셋 에서만 작동한다고 말한다. (요약부에서 feature는 모델을 설계할 때 사용되는 다양한 layer들을 이야기 한다) 이 중에 범용적이게(모든 모델 구조에서 영향력을 가질 수 있는) 사용되는 기술을 설명한다. 가장 먼저 BatchNomalization을 이야기하고 WRC (Weighted-Residual-Connections), CSP (Cross-Stage-Partial-Connections), CmBN (Cross mini-Batch Normalization), SAT (Self-Adversarial-training) 및 Mish-activation 등이 이러한 범용성을 가질 수 있는 feature라고 말하고 있다.
마지막으로 YOLO v4에서는 위의 범용성을 가지는 기능을 사용했으며 추가로 Mosaic기법의 데이터 증강기술, Drop block reqularization을 사용하여 성능을 향상 시켰다고 한다.
소개
저자는 CNN의 Object detection기술은 대부분 권장시스템(컴퓨팅파워가 높은)에서만 사용할 수 있다고 한다. (CSPNet의 목적과 같으며 요즘 모델 경량화가 대세라는 걸 느낄 수 있는 부분이다.) 예를 들면 빈 주차 공간을 찾는 모델은 느리고 정확도가 높지만 자동차 충돌을 경고하는 모델은 빠르고 부정확하다는 것이다. (한가지의 조건이 늘 부족한 상황에서 사용된다는 뜻)
detector의 정확도의 향상만이 recommendation systems 생성의 힌트가 되는것은 아니라고 한다. stand-alone 프로세스를 관리하는 것과 사람이 입력해야하는 부분을 감소시키는 것 추천시스템을 만드는데에 도움이 된다고 한다. 실제로 가장 좋은 성능을 가진 모델은 realtime으로 돌아갈 수 없거니와 멀티 GPU를 사용해야한다고 한다. 그리하여 Real-time object detector를 만드는 이유는 컴퓨팅파워가 높지 않은 환경에서도 기존의 1-GPU를 가지고 활용할 수 있도록 목표한다고 한다.
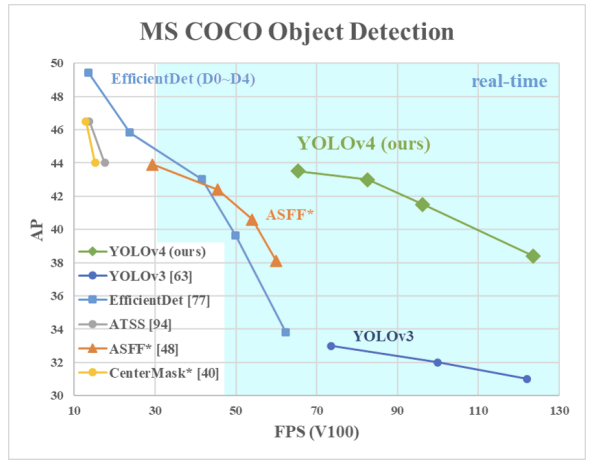
YOLOv4의 주된 목표는 제품 시스템에서 빠른 작동속도를 가져가면서도 연산량(BFLOP)의 숫자를 줄인다기보다 병렬적으로 최적화된 계산이 가능할 수 있게 하는 것이라고 한다. 저자는 데이터가 쉽게 훈련되고 사용 될 수 있기를 바란다며, YOLOv4를 사용하면 누구나 기존의 GPU를 가지고 위 figure1의 결과를 Realtime 환경에서 얻을수 있다고 말한다.
YOLOv4 의 작업을 요약하자면 대략 이렇다.
1. 효율적이고 강력한 object detector를 1080Ti, 2080Ti같은 환경에서도 빠르고 정확하게 훈련시킬 수 있다.
(1080Ti도 2080Ti 도 엄청 비싼데.. ㅜㅜ)
2. detector의 훈련과정에서 Bag-ofFreebies 와 Bag-of-Specials methods 의 영향을 검증한다.
3. SOTA의 method를 수정하고 만듦으로써 single GPU 훈련에서도 적합하고 효율적이게 한다. 이 과정에는 CBN,PAN,SAM
같은 기술들이 포함된다.

Related work
역시 Related work part에서는 역시 YOLOv4와 관련된 일이 적혀 있다. CSPNet 논문에서는 Method 부분을 읽어보며 어떻게 설계되었는지가 중요하기에 넘어갔지만, 이번 논문에서는 Computer Vision의 중요한 것들이 많이 언급되고 있기 때문에 체크를 하면서 넘어가는 것이 이 포스팅을 읽게 된 사람에게 도움이 될거라고 생각한다. 이미 잘 알고 있는 사람들이라면 가볍게 패스해주자.
Object detection models
큰 목록을 통해 논문에 기재되어있는 유명 모델들을 체크하며 넘어가 보자.
Backbone
GPU 플랫폼의 백본 : VGG, ResNet, ResNeXt, DenseNet 등
CPU 플랫폼의 백본 : SqueezeNet, MobileNet, ShuffleNet 등
Detection head
2-stage model : R-CNN, R-FCN, Libar R-CNN 등
anchor-free 2-stage model : RepPoints
1-stage model : YOLO, SSD, RetinaNet
anchor-free 1-stage model : CentorNet, CornerNet, FCOS 등
Detection neck
(detection neck은 백본과 헤드사이에 삽입되는 layer이며, 여러단계에서 feature map을 수집한다)
neck : FPN, PAN, BiFPN, NAS-FPN 등이 있다.
저자가 object detector 단계 별 method 에 대해 정리해둔 것은 이렇다.

Bag of freebies
오프라인 환경에서 훈련되는 모델들을 훈련방법만 변경하거나 훈련비용만 증가시켜 정확도를 높이는 방법을 "Bag of freebies"라고 부른다. object detector를 훈련 시킬때 사용되는 Bag of freebies는 데이터 증강 기법이다.
데이터 증강의 목적은 input 이미지의 가변성을 증가시키고, 설계된 모델이 다양한 이미지에 대해 높은 견고성을 갖게하는 것이다. 데이터 증강의 예로는 광도 왜곡(밝기, 대비, 색조, 채도, 노이즈추가 등), 기하 왜곡 (크기변화, crop, flip, rotate 등)
또한 데이터 증강에 참여하는 연구자들은 객체가 가려지는 이슈에 중점을 두며, classify나 detection에서 우수한 결과를 얻었다고 한다. Random 삭제 나 Cutout기법은 사각형 영역을 임의로 선택하고 무작위로 0또는 상보값을 채울 수 있다.
이러한 방법들 이외에도 style transfer GAN을 통한 데이터증강으로 texture bias 를 훈련과정에서 줄여 줄수 있다고 한다.
마지막 bog of freebies는 BBox를 regression할 때 사용되는 함수들인데, 논문에는 IOU,GIOU(generalized-IOU),DIOU(distance-IOU),CIOU(centor-IOU) 에 대해 이야기한다.
Bag of specials
플러그인 모듈과 post-processing을 통해 inference cost를 약간 증가시키지만 정확도를 크게 향상시킬 수 있는 방법을 bag of specials라고 부른다. 일반적으로, 이 플러그인은 특정 속성을 강화하기 위한 것이며, 그것들은 receptive field확대, attention mechanism도입 또는 feature intergration capability 강화 등이다.
(Bag of specials 부분에서는 자세한 설명은 생략하고 모듈명들을 나열하겠다. 필요시 논문을 확인하길 바란다.)
receptive field강화 에 사용되는 모듈로는 SPP(Spatial Pyramid pooling), ASPP, RFB(receptive field block)가 있다.
attention mecahnism에는 기존에 사용되던 SAM, FPN이 있으며 SFAM,ASFF,BiFPN이 있다고 한다.
활성화 함수의 변경 또한 이 분야의 연구에서 활발하게 진행되며, 기존 가장 많이 사용되는 ReLU부터 LReLU, PReLU, ReLU6,SELU,Swish,hard-Swish,Mish 등이 있다. (이부분은 그림으로 한번 보자.)

마지막으로, post-processing 방법으로는 NMS가 있다고 한다.
긴 논문의 글을 한글로 짧게 정리하다보니, 논문의 주요 내용보다 길어져 버릴 수도 있을 것 같다. 하지만 이 부분은 최신논문이기에 얻을 수 있는 정보가 많고, 읽어서 나쁠 것은 없다. 이제 드디어 YOLOv4가 어떻게 만들어 졌는지 확인 해보도록 하자.
Methodology
YOLOv4의 기본적인 목표는 위에서 언급했듯, 이론적 지표인 BFLOPS를 줄이는 것이 아니라 시스템내에서 병렬계산을 위한 최적화와 신경망의 빠른 작동속도를 가지게 하는 것이다.
Selection of architecture
아키텍쳐를 선택하는 일은 우리가 목표하고자 하는 일에 따라 매우 중요하다고 말한다. 예를 들면 CSPResNeXt50은 ImageNet 데이터에서 이미지 분류하는 일은 CSPdarknet보다 뛰어나다. 그러나 CSPdarknet이 MSCOCO데이터에서 객체를 찾아내는 일에는 CSPResNeXt보다 뛰어나다.
다음 우리가 해야하는 일은 Receptive field를 강화시키는 모듈을 선택하는 것이라고 말한다.
- 네트워크의 input사이즈 를 높게 가져갈 수 있는 것 (작은 객체를 감지하기 위함)
- layer 증가 가능 여부 (receptive field에서 네트워크의 input 사이즈가 증가 되기 위함)
- 파라미터 증가 가능 여부 (단일 이미지에서 크기가 다른 여러 객체를 감지할 수 있기 위함)
저자는 SPP block을 CSPdarknet53에 추가 했다고 말한다. 이것은 receptive field를 증가 시키고 중요 context 기능을 분리하여 operation의 속도를 유지할 수 있다고 한다. YOLOv4는 YOLOv3에 사용된 FPN대신 PANet을 사용하여 backbone level에서 다양한 detetor level 로 집계 시킬 수 있게 한다.
결과적으로, YOLOv4는 CSPdarknet53을 backbone으로 SPP block을 추가했으며, detection neck으로 PANet을 사용하고, detection head는 YOLOv3의 아키텍쳐를 따른다고 한다.
YOLOv4는 Cross-GPU Batch Normalization나 비싼 특수장치를 사용하지 않고 1080Ti와 2080Ti 에서 연구 되었다고 한다.
Selection of BoF and BoS
detector의 훈련 성능을 증가 시키기 위해 BoF와 BoS를 선택해야 한다. 위에서 언급한 다양한 활성화 함수 중 PReLU와 SeLU는 훈련하기 어렵고 ReLU6는 양자화 네트워크를 위한 활성화 함수 이므로 후보에서 제거 했다고 한다.
Drop block은 이미 많은 정규화 방법중 많은 승리를 거두었으므로 Drop block을 사용하는 것을 망설이지 않았다고 한다.
(drop block은 drop out 과 같은 방식이라고 생각하면 되는데, drop out이 일정 feature들을 훈련시 빼고 훈련하는 반면, drop block은 이름 그대로 feature의 묶음(?) 즉 feature의 일정 범위를 훈련시 빼고 훈련한다고 생각하면 된다.)
Additional improvements
여러가지 기능을 추가하여 single GPU에서 적합하게 설계했다고 한다.
- 데이터 증강 : Mosaic기법, SAT(self-adversarial training)|
- genetic알고리즘 적용 및 최적의 하이퍼 파라미터 선정
- 기존의 method를 효율적으로 사용 가능하게 수정 : SAM수정, PAN수정, CmBN(Cross mini-batch Normalization)도입

Cutmix를 이용하여, 2가지의 이미지 input을 외부의 객체를 감지한다. 추가로, Mosaic방식을 이용하여 위 그림과 같이 4가지의 다른 이미지 input을 가져가기 때문에 mini-batch의 크기를 크게 가져갈 필요가 없어진다고 한다.
SAT 방식은 2개 단계의 forward pass와 backward pass에서 일어나게 되는데 첫 번째 단계에서는 가중치를 가져가는 것 대신에 원본 이미지를 변경한다. (이 작업은 원본 이미지에 객체가 없다는 속임수를 만들게된다.) 두번째 단계에서는 1단계에서 수정된 이미지를 detection하는 훈련을 진행한다. (즉, 이러한 과정은 propagation과정에서 데이터를 증강 시킬 수 있다.)

CmBN은 CBN의 수정된 version이라고 한다. 위 그림에서 볼 수도 있지만 그림만 봐서는 무슨 소리인지 알길이 없으니 간단하게 적어보면 이렇다. 가중치들의 statistic을 수집하는 과정이 단일 배치내에서만 일어난다는 것이다. (글로 써도 뭔소린지 모를 수도..)

SAM 구조를 수정하여 사용하였다. 공간을 attetion하는 SAM을 point를 attention할수 있게하고 shortcut connection을 사용하는 PAN을 concatenation(연결)로 변경했다고 한다.
YOLOv4
이제 YOLOv4가 어떤 생각을 가지고 짜여졌고 어떤것들이 변경되었는지 알아보았다 이것을 한번에 정리하자면 이렇다.
- Backbone : CSPDarkNet53
- Detection Neck : SPP,PAN
- Detection Head : YOLOv3
- Used BoF for Backbone : CutMix, Mosaic, DropBlock, Class label smoothing
- Used BoS for Backbone : Mish활성화함수, CSP, Multi-input weighted residual connections
- Used BoF for detector : CIoU-loss, CmBN, DropBlock, Mosaic, SAT, Grid 감도 제거,
하나의 ground truth에 Multi앵커 사용, Cosine annealing scheduler, 하이퍼파라미터 최적화
- Used BoS for detector : Mish활성화함수, SPP, SAM, PAN, DIOU-NMS
여러가지 이러쿵 저러쿵 써있지만 연구된 detector의 좋은 것들을 다 때려박은 다음 최적화 시켰다는 이야기이다.
(물론 그게 엄청난 거지만.. )
이 것으로 detection에 사용되는 기술 부터 YOLOv4가 만들어지는 과정까지 YOLOv4논문을 통해 다뤄 봤다. 그 밑은 실험에 대한 내용이다. 논문의 꽃이자 자랑글인 실험 부분인데 저자가 이런 저런 실험을 통해 이런게 좋다라는걸 알아냈고, 그래서 위 내용이 이렇다~ 하며 표를 통해 그걸 증명하는 부분이다. 굳이 전부 읽어볼 필요는 없으므로 이전 포스팅과 같이 슥~ 보고 포스팅을 끝내겠다.
Experiments

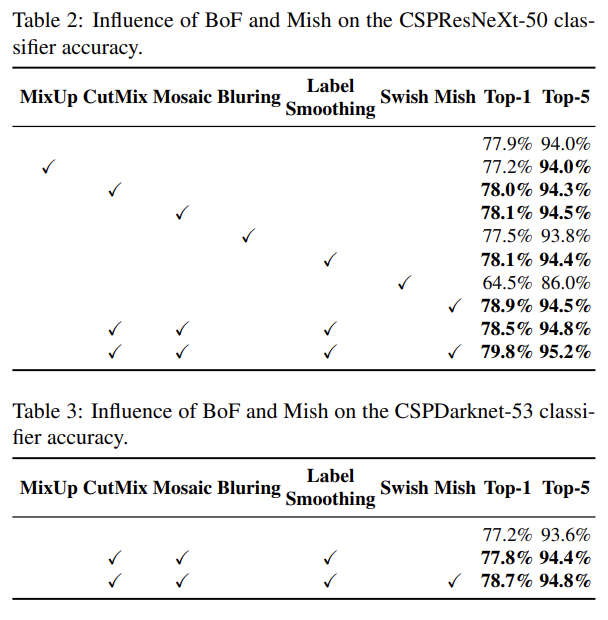

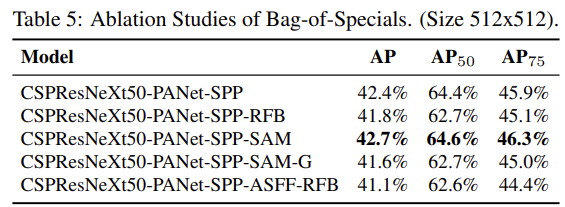



이상으로, 논문 리딩의 대한걸 마치겠다. 결론은 당연히 고로 YOLOv4가 짱이다. 라는 내용이기 때문에 넘어가도록하고, 이전 포스팅과 마찬가지로 AlexAB의 기재되어 있는 config파일을 통해 변화된 모습을 확인하면서 끝내겠다.
이전 포스팅의 경우 한 부분만 확인하면 되었기에 직접 gedit을 통해 확인하였지만 이번에는 좀 더 가시적으로 확인하고 쉽게 이해하기 위해 netron이라는 사이트를 이용해서 구조를 확인해 보자.

위 그림은 보면 Input단계에서 이루어지는 layer의 구조이다. 구조를 보면 논문에서 언급한대로 mish 활성화 함수를 사용하고 있으며, 이전 포스팅에서 보았듯이 2개의 파트로 나누어 마지막 trasition단계에서 합쳐지는 CSP 구조를 띄고 있다.
그리고 backbone의 구조가 쭈우욱 이어지다가, 후반부를 보면 이런 부분이 있다.
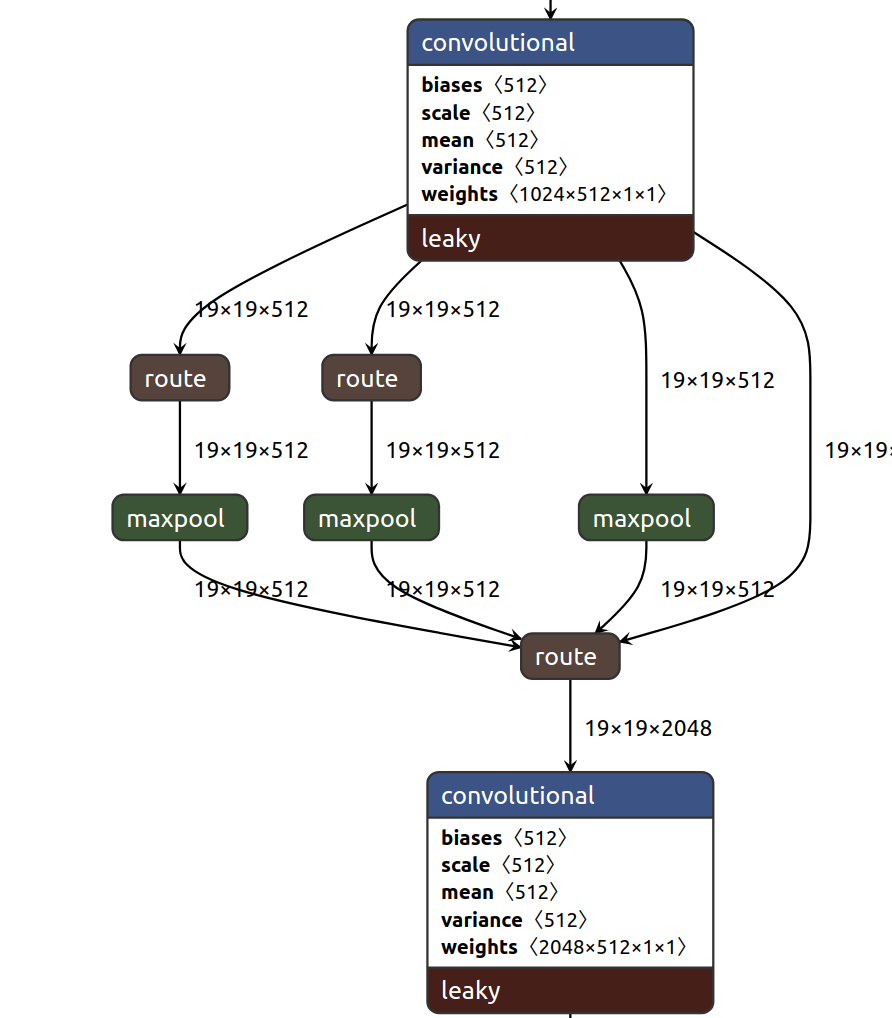
바로 이 부분이 논문에서 CSPDarkNet에 추가했다고 하는 SPP block이다. 더 하단부로 내려가보면

왼쪽 이미지의 YOLOv3와 비교해서 YOLOv4는 detection level로 내려올때, shortcut이 아니라 route를 통한 concat을 한다는 것을 알 수 있다. 이는 논문에서 언급된 PAN을 수정한 부분이라고 볼 수 있다.
마지막으로 가장 밑단의 detection head부분을 보면

가장 밑쪽에 있는 detection head부분을 보면 논문에서 언급된 대로 YOLOv3와 YOLOv4가 같은 구조를 하고 있다는 것을 볼 수 있다. (leakyReLU의 사용이나 구조의 모습이 같다.)
P.S.여기까지 읽어주신 분이 있다면, 굳이 열심히 포스팅글을 남긴 보람이 있을 것같네요. 읽으신 분도 시간 절약이 많이 되었을거라고 생각합니다. 감사합니다!
'지식 저장소' 카테고리의 다른 글
| Imbalance Problems in Object Detection : 객체 검출 분야의 불균형 문제 A Review(3) (0) | 2020.11.03 |
|---|---|
| Imbalance Problems in Object Detection : 객체 검출 분야의 불균형 문제 A Review(2) (0) | 2020.11.03 |
| Imbalance Problems in Object Detection : 객체 검출 분야의 불균형 문제 A Review(1) (0) | 2020.11.02 |
| DETR : End-to-end방식의 Transformers를 통한 object detection (2) | 2020.07.07 |
| CSPNet : CNN의 학습능력을 향상 시킬 수 있는 새로운 Backbone (4) | 2020.06.23 |



