들어가며 ..
이번 포스팅에서 다룰 논문 제목은 End-to-end Object detection with Transformers 입니다.
논문 요약을 작성하며 중요 부분에 대해 굵은 글씨로 작성하였고, 논문의 직접적인 내용이 아닌 개인적인 코멘트는 붉은색으로 작성하였으니 참고 바랍니다.
Abstract
논문의 저자는 object detection을 direct set prediction의 문제로 바라보는 새로운 방법을 제시한다. 그들의 접근 방법은 detection을 진행하는 일련의 파이프라인에서 수작업으로 만들어진 non-maximum suppression(NMS는 하나의 객체에 중복된 prediction을 제거하는 작업을 한다)이나 앵커를 생성하는 과정을 효과적으로 제거했다. 논문의 저자는 DEtection TRansformer(DETR)이라고 부르는 새로운 프레임 워크를 제안한다.
프레임워크의 주요 특징은 set 기반의 global loss이고, 이것은 encoder-decoder구조를 가진 transformer 가 이분법을 통한 unique prediction을 갖게 한다.
작은 set에서 객체를 찾아야 할 때, DETR은 객체와 전체 이미지의 관계에 대해 병렬적으로 final set 예측을 직접적으로 Output으로 내보낸다.
이 새로운 모델 (DETR)은 단순한 컨셉을 지니고, 특수한 library를 필요로 하지 않는다고 한다. DETR은 MSCOCO 데이터셋에서 Faster R-CNN만큼의 정확도와 run-time성능을 보여준
다고 한다. 또한, DETR는 panoptic segmentation(일반적인 시맨틱 segmentation은 class별로 segmentation을 하게 되는데 panoptic segmentation은 class별 segmentation에서 더 나아가 인스턴스별로 segmentation 하는 것)이라고 보면 된다.을 쉽게 일반화할 수 있다.
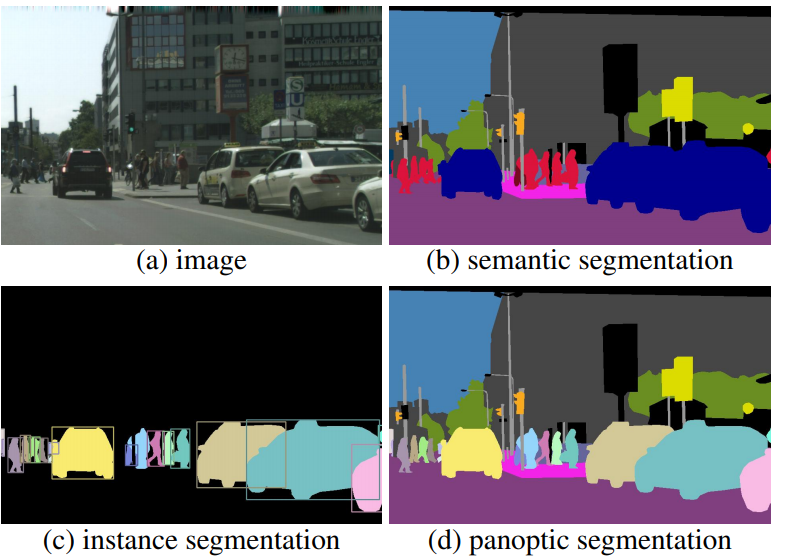
간단하게 정리하면 새로운 transformer를 사용하는 detection 프레임워크를 만들었고, Faster R-CNN과 성능차이가 없다고 하고 있는데, 자세한 내용은 논문의 전체 내용을 보면서 파악해야할 듯 하다.
Introduction
논문의 저자는 소개의 첫부분에서 object detection의 목표는 BBOX 및 label 예측을 하는 것이라고 말한다. 최근 detector들은 예측을 하는 작업에서 간접적인 방식을 취하는데, 그것은 앵커나 window center에서 surrogate regression와 classification으로 처리하는 것이다.
논문의 저자는 최근 detector들의 성능은 앵커set으로 BBox를 생성하는 방법이 heuristic하기 때문에 postprocessing 부분의 중복된 예측을 제거하는 곳(NMS 부분)에서 영향을 많이 받는다고 한다.
여기까지 읽어보면, 이 논문의 방향성은 파이프라인 간소화 및 heuristic 부분을 제거 하는 것 에있다는 것을 알 수 있다.
end-to-end 방식은 번역머신이나 음성인식에서 주로 사용되었지만 아직 object detection에서는 사용되고 있지 않았다. 이전의 연구들은 prior knowledge을 추가하거나 까다로운 형태와 경쟁하지 않는다고 한다.(최근의 논문들이 기존의 conv-net의 틀을 벗어나지 않으려는 것을 말한다.) 이 논문은 그러한 격차를 해소하는 것을 목표로 한다.
즉, end-to-end방식을 object detection 분야에 도입시키면서 다른 detector보다 새롭다는 것을 어필하는 듯 하다.

요약에서도 언급했듯, 논문의 모델은 direct set prediction으로 object detection을 바라본다. 이 모델은 인코더-디코더 구조를 기반에 두는 transformers 를 채택하여 sequence한 prediction을 가진다고 한다.
transformer의 Self-attention 메커니즘은 sequence의 모든 요소가 쌍으로 소통하며 중복된 prediction을 제거하는데 적합하다고 한다.

이러한 구조는 실제로 번역머신의 가장 기본적인 형태라고 할수 있는데, seq2seq 구조를 object detection 분야에 적용한것으로 보여진다.
학습과정에서는 CNN을 통해 생성된 feature들이 인코더에 들어간 후 디코더에 전달이 되면 ground truth 데이터를 통해 Box의 형태로 훈련하게 되고, 그것들이 prediction이 되는 것이다. 이 과정에서 Self-Attention을 통해 feature들의 연관성을 찾아내므로 여러개가 아닌 객체당 하나의 prediction이 나오게 된다.
DETR은 모든 객체를 한번에 예측한다. 그리고 ground-truth와 prediction사이에서 end-to-end의 set loss를 통해 이분 매칭을 훈련한다. DETR은 수작업(앵커나 NMS같은 작업) 컴포넌트가 없기 때문에 간단한 파이프라인을 가진다. 다른 detector모델과 다르게 DETR은 customized layer가 필요하지 않아서 표준의 CNN 및 transformer 재구현하기가 쉽다.(이들은 딥러닝 라이브러리에 구현되어 있는 Transformer와 ResNet구조를 그대로 사용하였다고 한다.)
Direct set prediction 작업을 하는 대부분의 모델과 DETR을 비교했을 때, DETR의 특징은 병렬 디코딩을 통해 이분매칭을 한다는 것이다. RNN의 경우 autoregressive(자기회귀)에 포커스를 맞췄는데, DETR은 의 loss function은 predict할 때, predicted object의 순열이 변하지 않기 때문에 병렬적으로 작동한다는 것이다.
DETR은 COCO dataset에서 Faster R-CNN을 기준으로 굉장히 경쟁력이 있다고 한다.
정확하게는 DETR은 Large object에 대해 좋은 퍼포먼스를 나타내며, 이 결과는 local 계산을 하지 않기 때문에 가능하다고 한다. 하지만 small object대해서는 낮은 퍼포먼스를 나타낸다고 한다. 이들은 후에 FPN을 통해 개선하고자 한다.
NMS나 앵커를 사용하지 않기 때문에 image-level에서도 작은 객체의 feature는 인코더-디코더까지 명확하게 전달되기 힘들것이다. Pyramid구조로 해결할 수 있다고 적혀 있기에 나중에 해결되면 성능이 좋아질것 같다.
소개의 마지막 부분에서는 DETR은 어려운 작업을 쉽게 확장시킬 수 있다고 하는데, 이들은 segmentation의 head부분을 pre-trained DETR의 외형을 이용해서 Panoptic Segmentation 에서 경쟁력을 가질 수 있었다고 한다.
Related work
2.1 Set Prediction
컴퓨터 비전 분야의 정식 딥러닝 모델 중 직접적인 predict를 하는 모델은 없다. 보통의 모델은 multilabel classification(one-vs-rest같은 방식으로 분류 작업을 한다.)을 통해 예측을 한다. 이러한 모델은 요소들 사이에 가려진 구조를 detection하기 어렵다. 어려움의 첫번째 이유는 가까운 중복 prediction을 피하기 때문이다. 대부분의 detector들은 NMS같은 post-processing방법을 사용하는데 direct set prediction은 post processing 방법을 사용하지 않는다. 대부분은 detector는 global inference 과정에서 요소들간의 상호작용의 여분을 남기는걸 피한다. 일정한 사이즈 set 을 prediction하는 모델은 dense층으로 이루어진 fully connected network가 존재하고 이것은 global inference하기에 충분하지만 비용이 비싸다. RNN의 경우 auto-regressive(자기추론) 시퀀스 모델을 이용하기 때문에 loss function은 변하지않는 순열의 prediction을 한다. 이러한 구조는 target 값에 대해 unique한 매칭을 가져오기 때문에 병렬적 predict가 가능하다.
2.2 Transformers and Parallel Decoding
Transformers는 Vaswani에 의해 기계번역의 attention기반의 block으로 소개되었다. Attention 메커니즘은 input 시퀀스의 집합정보 layer이다. transformers는 self-attention layer를 가지고 있고 이것은 각각의 요소들을 검사하여 집합정보 layer를 업데이트 하기에 non-local 네트워크와 비슷하다. attention기반의 모델의 가장 큰 이점은 global한 계산으로 완벽한 메모리를 사용한다는 것이다. 이는 RNN같은 긴 시퀀스 모델에 적합하다. transformers는 현재 NLP,음성처리, 컴퓨터 비전 분야에서 RNN의 문제점을 대체할 수 있는 수단이다. transformer는 처음으로 seq2seq 모델(1대1매칭의 output을 생성하는 모델)에 자기추론 모델을 사용하였다.
the prohibitive inference cost(입력길이와 출력길이가 비례하고 배치하기 어려운 작업)은 오디오, 번역머신, 단어 표현 학습 그리고 최근에는 음성인식 영역에서 병렬 시퀀스를 생성하는 것이 개발되고 있다. transformer와 병렬decoding을 결합하는 일은 계산 비용과 global계산 사이에서 trade-off되는 것에 적합하다.
2.3 Object detection
최근 object detection 방법으로는 2-stage detector의 경우 proposal을 이용하고, 1-stage detector의 경우 앵커를 이용하거나 grid를 통해 object의 중심을 찾는다. 최근 연구(본 글에서는 앵커와 앵커-free의 격차를 연구한 논문을 말한다)에서는 1-stage detector는 최초로 object를 찾아낼 때, 앵커 또는 grid이용 과정에 크게 의존한다고 증명했다. DETR은 이런 과정을 제거하고, 앵커대신에 input이미지에서 절대적인 box를 예측한다.
Set-based loss
몇몇의 detector는 이분매칭 loss를 사용하지만, 이 것은 convolution 이나 fully-connected layer 의 서로 다른 prediction의 연관성을 수작업(수작업이라 표현되는 이유는 k-means같은 군집화 전략으로 앵커사이즈를 직접 생성하기 때문이다.)의 NMS post-processing로 퍼포먼스 향상을 시킬 뿐이라고 한다.
direct set losses를 사용하면, 더 이상 NMS과정이 필요없다고 한다. 논문의 저자들이 prior정보를 줄이는 방법을 찾는동안 몇몇의 detector들은 아직도 proposal box를 수작업으로 추가하고 있다고 한다. (매우 비웃는 느낌의 멘트이다..)
Recurrent detectors
DETR과 비슷한 detector가 있지만 그들은 작은 dataset에서 평가되었으며 최신 기준에는 평가되지 않았다. 그들은 RNN구조를 사용하지만 병렬 decoding에 전혀 좋은점이 없다.
The DETR model
3.1 Object detection set prediction loss
DETR은 N개의 고정된 prediction을 추론한다. decoder를 지나는 1개의 pass는 이미지의 object 숫자보다 더 커진다. 논문의 저자가 가장 어려웠던 점은 ground truth에 맞춰 예측된 object와의 score를 훈련시키는 것이었다고 한다. 제안되는 loss는 이분매칭 과정을 통한 BBox를 예측에 최적화 되었다.

위 식을 설명하면, y가 ground truth 라고 할 때 y은N개의 prediction set이다. 이때, N은 이미지내의 객체 수 보다 많아지므로 y에 N크기가 되게끔 ∅(no object)를 추가한다. 하나의 요소가 N요소의 순열에 포함 되는 것을 이분 매칭을 통해 찾았을때, cost가 가장 낮게 된다.
쉽게 풀자면, ground truth에 N의 크기가 될 수 있게 ∅(no object)가 추가되고, transformer의 디코더가 예측하는 객체의 class가 ground truth 객체에 포함이 될때, loss가 낮아 진다.
ground truth 데이터를 yi=(ci,bi)라고 할때, ci가 클래스 label이 되고, bi가 box중심 좌표와 높이 넓이를 가진다고 하자. prediction 요소인 (i)의 클래스는 p(i)(ci) 로 표현하고, box는 b(i) 로 표현할 때, Lmatch(yi,y(i))는

로 표현된다. 이런 과정은 다른 detector와 다르게 중복되는 prediction이 나오지 않는다. 이 후 Hungarian loss(헝가리안 loss는 이분 그래프에서 모든 정점에 대한 potential의 합이다.)로 모든 쌍을 매칭하며, linear combination of a negative log-likelihood 를 통해 class와 box의 loss를 정의 한다.

그 후 클래스가 ∅(no object)일 때, 가중치에 10배의 감소를 준다고 한다.
클래스가 ∅(no object)일 때 prediction에 영향이 없기 때문에 비용이 일정하다고 한다.
그리고 클래스가 정답일 경우에는 log p(i)(ci)를 사용한다고 한다.
box를 예측할때 L1 loss는 큰상자와 작은상자의 오차가 유사하더라도 다른 scale을 가지기 때문에 L1 loss와 GIOU loss를 조합하여 scale 을 다양하지 않게 만듦으로 이런 문제를 완화 했다.
box의 경우에는 예측값과 ground truth의 차이(L1 loss)와 함께 IOU계산을 사용한다고 생각하면 된다.
결론적으로,

=
![]()
로 표현된다.
이 두개의 loss는 내부 batch의 개수에 따라 정규화 된다.
3.2 DETR architecture
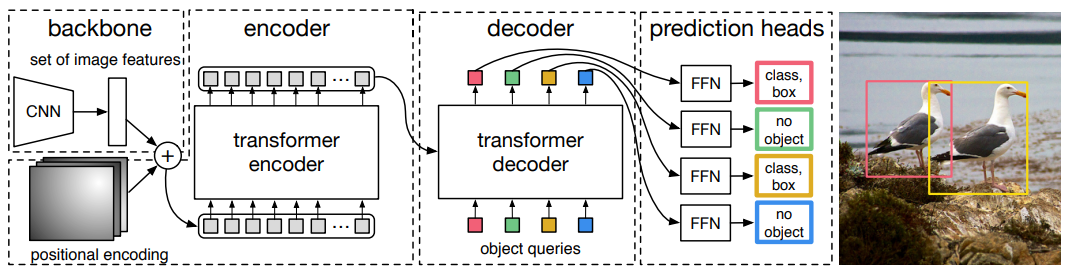
DETR의 구조는 간단하다. CNN백본(논문의 저자는 ResNet을 사용했다.) 모델을 통해 feature맵을 생성하고 인코더-디코더 transformer를 거친다음 FFN(feed forward network)을 통해 결과값을 출력한다. DETR은 굉장히 간단한 구조를 가져서 PyTorch 코드로 50줄도 안된다고 한다. 그들은 이러한 단순한 방법이 새로운 detection연구자에게 매력적으로 느껴지길 희망한다.
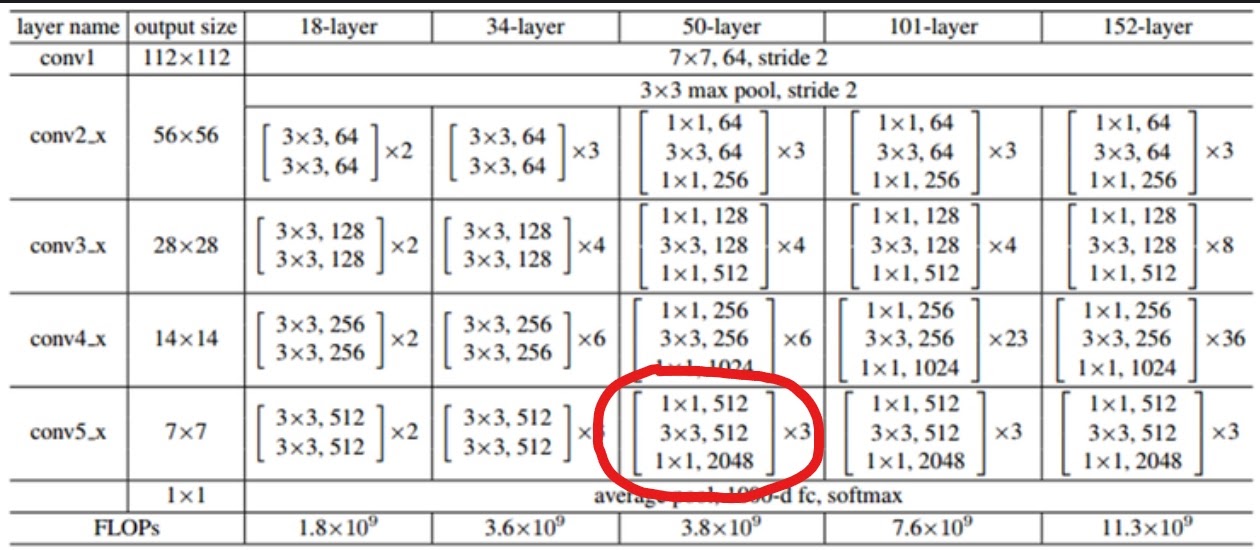
Backbone은 CNN연산을 통해 작은 해상도의 활성화 맵을 생성한다. 그들의 마지막 채널수는 대부분 2048에 마지막 크기는 Height/32, Width/32 이었다고 한다.
ResNet의 끝 conv layer가 2048이기 때문이다.
Transformer는 인코더-디코더 구조의 전형적인 구조를 따른다. 이 Transformer를 통해 이미지의 모든 object를 한번에 추론한다. 마지막 prediction에 있는 FFN은 이름대로 perceptron으로 이루어진 NN이고, 3층의 layer로 ReLU활성화 함수를 사용한다. ∅(no object)가 클래스에 추가 되었기 때문에 배경을 알아내는 것에도 사용될 수 있다.
Decoding을 도와주는 loss로는 위에서 언급 했듯 디코더 뒤에 FFN과 Hungarian loss를 추가하여 FFN끼리 매개변수를 공유하기 때문에 다른 디코더 layer에서의 예측 FFN을 정규화 한다고 한다.
Experiments
실험 파트의 실험 요건을 정리하자면 이렇다.
비교 모델 : Faster R-CNN
Dataset : COCO minival
Optimizer : AdamW (Faster R-CNN의 경우 SGD)
Backbone : ResNet50(pre-train ImageNet), ResNet101(pre-train ImageNet)
추가 기능 : Conv5 layer의 stride를 삭제하고 resolution을 증가시킴(이름에 DC5가 붙은 부분)
Scale augmentation(input 이미지를 480px~1333px까지 resize)
Random crop augmentation
Add dropout 0.1 (transformers)
훈련 GPU : 16개의 V100 GPU
훈련 epoch : 300 (Faster R-CNN의 경우 500)
훈련 시간 : 72 시간

4.1 Comparison with Faster R-CNN
표를 보면 AP75,APs에서 Faster R-CNN이 높고 나머지는 DETR이 높다.
논문의 내용대로 작은object에서 약한성능을 보이고 있다. AP75는 사실 차이가 없다.
하지만 확실히 APL에서 DETR이 훨씬 좋은 성능을 보여주고 있다.
연산량 측면에서 보면 DETR이, FPS에서는 Faster R-CNN이 좋은 성능을 보인다.
하지만 이 두 모델 모두 Real-time이나 경량화가 목표가 아니라 비교대상은 아니다.
‘+’마크가 붙은 Faster R-CNN은 3배의 시간을 더 훈련시켰다고 한다.
4.2 Ablations
Number of encoder layers

인코더의 크기에 따른 영향을 나타낸 표. 인코더의 layer수가 늘어날 수록 AP가 증가하는걸 확인할 수 있다.
이런 실험결과를 통해 (인코더 layer 6개를 기준으로) 인코더 layer가 없을때는 AP의 경우 -3.9point , APL의 경우 -6.0까지 떨어 지는 것을 확인했고, self-attention이 있는 인코더 layer의 개수가 영향을 끼치는 것을 알아 냈다고 한다.

위 그림을 보면 인코더의 self-attention과정을 볼 수 있는데, 이렇게 인스턴스가 잘 나누어 진다면 디코더에서 object의 위치와 클래스를 예측하는건 매우 쉬운일이 된다고 한다.
Number of decoder layers.

또한 이들은 object를 detection할 때, 디코더의 단계가 매우 중요하다는 것을 알아 냈다. 위 그래프를 보면 첫번째 단계와 마지막 단계의 차이가 크다는 것을 알 수 있다.
이 것은 하나의 디코더만 있는 transformers는 output 요소들 간의 연관성을 계산할 수 없다(하나의 object에 중복된 prediction이 생성되기 쉽다는 의미이다.)는 것을 설명한다.

위 그림을 보면 디코더 attention은 상당히 지역적이라는 것을 알 수 있다고 한다. 다른 색상으로 디코더의 prediction을 표시하였는데, 보는바와 같이 object의 head나 legs 쪽을 attention하는 것을 확인 했다고 한다. 논문의 저자는 인코더가 global하게 attention하여 object의 인스턴스를 분리하는 반면 디코더는 object의 경계를 추출하기 위해 head와 legs에 attention한다고 말한다.
Importance of FFN
transformer구조 내에 있는 FFN은 1x1conv와 비슷하게 볼 수 있다. (1x1conv의 모습을 생각해보면 bottleneck구조에서 차원이 줄었다가 늘어나는 형태와 비슷하다고 하는것 같다.)이것은 인코더와 비슷하게 attention증가를 만든다. 논문의 저자가 FFN을 지우고 테스트를 해보았더니 파라미터의 수는 줄었지만 AP는 2.3만큼 떨어졌다고한다. 이것만으로도 FFN의 중요성을 알 수 있다.
Importance of positional encodings

위 표는 self-attention이 달린 부분(이 글에서는 SA부분이라 하겠다.) 과 출력 부분에 변화를 주며 실험한 결과이다. 이 중 인코더의 출력부분은 삭제 할 수 없어 실험 대상에는 뺐다고 한다. 표의 내용은 아래와 같고, 수치는 표를 통해 확인할 수 있다.
첫번째 : SA부분을 모두 제거한 실험
두번째 : input으로 전달
세번째 : attention을 학습하여 전달
네번째 : 인코더의 SA를 제거 하고 고유의 attention 전달
다섯번째 : SA는 고유의 attention을 모두 전달받고, 출력 부분은 항상 학습
Loss ablations

위 표는 Loss function에서 L1 loss와 GIOU loss 를 켜고 끄며 실험한 결과 이다. 이러한 실험결과를 통해 본 논문에서 사용하는 Loss function이 어떻게 나왔는지 알 수 있다.
4.3 Analysis

Decoder output slot analysis
위 그림은 COCO 2017 val 데이터셋의 서로 다른 slot으로 예측한 box의 위치들을 시각화 한 것이다. DETR은 쿼리 slot마다 다른 것을 학습한다. 각각의 slot에는 box의 영역이나 크기를 다르게 focusing 하는 mode들이 있다고 한다.
DETR은 중심점과 높이,넓이로 output이 나오므로 위 그림은 box의 중심점 들의 위치를 표현한 것으로 볼 수있다. 가운데에 빨간점이 있는 걸 보면 이미지 전체에 box를 그리는 mode도 있다는 것을 알 수 있다.

Generalization to unseen numbers of instances
COCO데이터의 어떤 class들은 한 이미지에서 많은 인스턴스들이 존재하지 않는다고 한다. 예를들면, 13마리의 기린이 있는 데이터는 없다. 결국 이미지를 새로 생성해서 사용했는데, 예측 결과에서 각 object 쿼리 들이 class-specialization에 강하지는 않다(클래스별 인식이 아닌 인스턴스별 인식으로 이어 진다.)고 한다.
4.4 DETR for panoptic segmentation
DETR은 panoptic segmentation에 이용 될 수 있는데 원래 DETR의 구동 방식 대로, Box를 예측하고 mask head를 달아서 segmentation을 진행한다.(labeling 을 box도 하고 segmentation도 해야 하는 상황이 되는 건가.. 하는 생각이 든다.)
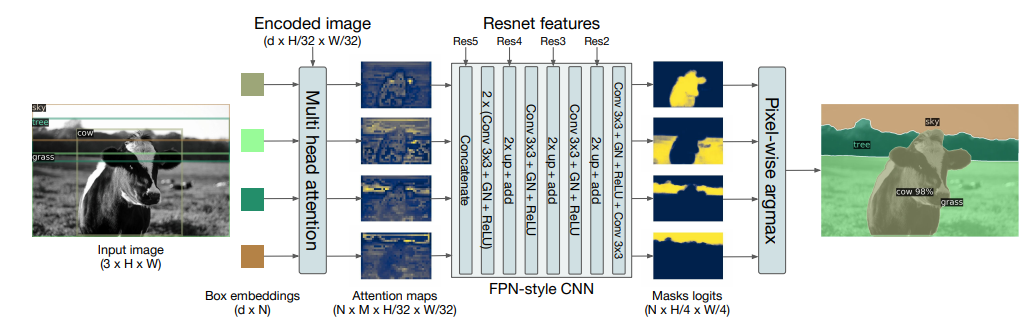
구조를 그림을 보면 DETR의 output이 input이 되어 FPN-style CNN으로 들어가게 되고, 인스턴스 별 출력으로 나오는 mask를 합쳐 output을 생성하는 구조이다. mask를 생성할 때는 DICE/F-1 loss 와 Focal loss를 사용한다. 논문에는 DETR의 box예측 가중치를 완전동결 시키고 mask head만 25epoch 훈련 시켰다고 한다. 그 결과는 아래의 표와 같다.

DETR은 panoptic segmentation 결과를 생성할때, mask의 점수를 argmax를 통해 해당 mask에 할당한다고 한다. 이러한 과정은 최종 mask가 겹치지 않게 해준다.
Training details
훈련 모델 : DETR, DETR-DC5, DETR-R101
데이터셋 : COCO panopic
훈련 epoch : DETR(동결), mask head(25)
Mask 진행과정
1. 85% 신뢰도로 필터링
2. 픽셀 당 argmax 계산
3. 빈 마스크 필터링
4. 마스크 하나로 축소
Main results

위 그림과 Table5가 DETR panoptic segmentation 의 결과이다. 저자는 향후 연구에서 완전히 통합된 panoptic모델을 연구할 때, 이러한 DETR의 접근방식이 도움이 되길 바란다고 한다.
Conclusion
Object detection 분야에서 end-to-end 방식의 새로운 구조를 제안했으며, DETR은 Faster R-CNN에 견주어 부족하지 않다고 한다. 또한, DETR은 panoptic segmentation으로 확장이 쉽고, 경쟁력있는 결과를 가진다. Large object에서는 Faster R-CNN보다 좋은 성능을 보여준다. 이러한 새로운 구조의 detector는 훈련, 최적화, small object 성능 개선등에 도전하여 향후에는 DETR의 성공적으로 될거라고 기대한다고 한다.
여기까지가 논문의 대한 내용의 포스팅이다. 포스팅의 마지막에는 늘 구조를 보면서 마쳤는데, 이번에는 그냥 논문의 대한 개인 의견을 작성하였다. 저~~엉말 개인적인 의견이므로 읽으신 분만 읽으면 될 것 같고, 논문의 내용만 필요하신 분이라면 가볍게 패스.
참조 : https://arxiv.org/pdf/2005.12872v3.pdf
논문에 대한 개인 의견
논문의 가장 핵심은 Object detection을 transformer 구조를 통해 풀어냈다는 것인데, 아이디어가 참신했다. 휴리스틱한 부분들을 없애고자 transformer를 이용 하는 것은 향후에도 충분히 가능성 있을 것 이다. 하지만 현재 논문에서는 구조적인 참신함에 신경을 많이 써서 그런지 아직은 성능면에서는 좋지 못해 보이는 것도 사실이다.

실제로 SOTA에 검색해보면 DETR-DC5의 BOX AP 위치는 그리 높지 않다. 참신한 구조를 통해 다른 detector와 비슷한 성능이 나오는 것은 대단하지만, 아직 선택받는 모델이 되기에는 연구가 좀 더 필요할 것이다. 최근 읽었던 2개의 논문이 모두 모델 경량화에 초점을 맞춘 논문이었던터라 16개의 GPU를 사용했다는 것 또한 매력적으로 느껴지지 않았다.
하지만 분야를 Object detection에만 두지 않고 확장 가능성을 제시한 것은 의미가 크다. panoptic segmentation의 경우 DETR이 특정한 측정 기준에서 1위인 것으로 확인할 수 있다. 또한, backbone이 ResNet으로 한정되어있고, 논문에 나온대로 FPN 적용 처럼 다양한 실험을 통해 성능을 개선할 여지가 많이 남아 있는것도 사실이다.
P.S.여기까지 읽어주신 분이 있다면, 굳이 열심히 포스팅글을 남긴 보람이 있을 것같네요. 읽으신 분도 시간 절약이 많이 되었을거라고 생각합니다. 감사합니다!
'지식 저장소' 카테고리의 다른 글
| Imbalance Problems in Object Detection : 객체 검출 분야의 불균형 문제 A Review(3) (0) | 2020.11.03 |
|---|---|
| Imbalance Problems in Object Detection : 객체 검출 분야의 불균형 문제 A Review(2) (0) | 2020.11.03 |
| Imbalance Problems in Object Detection : 객체 검출 분야의 불균형 문제 A Review(1) (0) | 2020.11.02 |
| YOLOv4 : Object detection의 최적의 속도와 정확도 (2) | 2020.06.24 |
| CSPNet : CNN의 학습능력을 향상 시킬 수 있는 새로운 Backbone (4) | 2020.06.23 |



