Yolo v3 설치하기
2020/04/17 - [Computer Vision/Object detection] - Yolo v3 설치하기
Yolo v3 설치하기
object detection 분야에서 유명한 yolo의 설치법 및 사용법을 작성한다. 모든 딥러닝 라이브러리가 마찬가지겠지만 yolo를 효율적으로 사용하기 위해서는 gpu를 사용하는 것이 좋다. 그래픽 드라이버와 Cuda설치..
keyog.tistory.com
Yolo v3를 설치하였다면 custom 데이터를 통해 나만의 모델을 만들어 보자.
필자는 AlexAB의 Github에 있는 Yolo mark를 이용하여 labeling하여 진행하였다.
https://github.com/AlexeyAB/Yolo_mark
AlexeyAB/Yolo_mark
GUI for marking bounded boxes of objects in images for training neural network Yolo v3 and v2 - AlexeyAB/Yolo_mark
github.com
labeling을 완료하여 데이터셋이 생성되었다면 yolo를 통해 훈련을 진행해보자.
Custom 데이터 Yolo로 훈련시키기
custom데이터를 훈련시키기 위해서는 가장 먼저 cfg를 수정해주어야 한다. 제공된 cfg파일이 coco데이터셋을 기반으로 되어 있기 때문에 사용하고자 하는 데이터셋에 맞춰줄 필요가 있다. 이 글에서는 필자가 훈련시킨 방법이 매우 상세하게 적혀 있으나 필요없는 부분을 생략하고 진행해도 무관하다.
cfg수정
이전에 설치한 darknet 디렉토리로 이동하여 cfg파일을 수정한다.
gedit cfg/yolov3.cfgcfg파일을 열면 첫 부분을 수정해준다 width와 height가 608 , 608로 되어있는데 이렇게 진행하면 gpu 메모리를 상당히 차지하므로 416,416로 수정해준다. 만약 본인의 메모리가 부족하다면 더 줄여도 상관없다. cuda memory에러시 batch size를 수정
[net]
# Testing
# batch=1
# subdivisions=1
# Training
batch=64
subdivisions=16
width=416
height=416
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.001
burn_in=1000
max_batches = 500200
policy=steps
steps=400000,450000
scales=.1,.1
첫 부분을 수정하였으면 Ctrl+f를 이용하여 yolo부분을 검색해서 수정해주면 된다. yolo 부분에 있는 classes와 yolo위쪽에 있는 filter의 크기를 수정해주면 된다.
classes는 훈련시키고자 하는 데이터셋의 class갯수, filter의 갯수는 (classes+5) * 3 으로 계산하여 적어준다. 필자의 클래스는 15개이고, filter의 갯수는 (15+5)*3 = 60개 이다.
[convolutional]
size=1
stride=1
pad=1
filters=60
activation=linear
[yolo]
mask = 0,1,2
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=15
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
yolo 부분은 총 3개가 있으므로 꼭 cfg파일에서 3개를 모두 찾아서 수정해줘야한다.
*anchor size의 경우 kmeans를 이용하여 본인의 데이터셋에 맞게끔 수정해줄 수 있다. 하지만 훈련을 충분히 시킬 수 있다면, 그냥 default로 설정되어 있는 coco데이터셋의 anchor size를 이용해도 된다.
훈련 파일 관리하기
cfg파일까지 모두 수정하였다면 본인의 커스텀 데이터의 맞게끔 names,data,train.txt파일을 수정해준다.
먼저 train.txt파일을 확인해보면,
x64/Release/data/img2/001_aaaa.jpg
x64/Release/data/img2/001_aaac.jpg
x64/Release/data/img2/001_aaad.jpg
x64/Release/data/img2/001_aaae.jpg
x64/Release/data/img2/001_aaaf.jpg
x64/Release/data/img2/001_aaag.jpg
x64/Release/data/img2/001_aaah.jpg
x64/Release/data/img2/001_aaai.jpg
이런식으로 되어있는 것을 알 수 있다. Yolo mark에서 진행했기 때문에 상대경로로 적혀 있는데 darknet폴더로 데이터셋을 모두 옮겨와서 사용해도 되지만 필자는 Yolo mark폴더에 접근하기 위해서 파일내용을 절대경로로 바꿔주었다.
jupyter notebook을 활용하여 train.txt를 절대경로로 변환해 주었다.
txt = open('/media/gopiz/extra/vision_project/darknet/custom/train.txt','r')
f = open('/media/gopiz/extra/vision_project/darknet/custom/train2.txt','w')
while True :
line = txt.readline()
if not line:
break
f.write('/media/gopiz/extra/vision_project/Yolo_mark/'+line)
txt.close()
f.close()
Output으로 나오는 train2.txt파일을 보면 절대경로로 변환된 것을 확인할 수 있다.
/media/gopiz/extra/vision_project/Yolo_mark/x64/Release/data/img2/001_aaaa.jpg
/media/gopiz/extra/vision_project/Yolo_mark/x64/Release/data/img2/001_aaac.jpg
/media/gopiz/extra/vision_project/Yolo_mark/x64/Release/data/img2/001_aaad.jpg
/media/gopiz/extra/vision_project/Yolo_mark/x64/Release/data/img2/001_aaae.jpg
/media/gopiz/extra/vision_project/Yolo_mark/x64/Release/data/img2/001_aaaf.jpg
/media/gopiz/extra/vision_project/Yolo_mark/x64/Release/data/img2/001_aaag.jpg
/media/gopiz/extra/vision_project/Yolo_mark/x64/Release/data/img2/001_aaah.jpg
/media/gopiz/extra/vision_project/Yolo_mark/x64/Release/data/img2/001_aaai.jpg
다음은 훈련을 위해 train set과 validation set을 나눠보자. 필자의 데이터셋은 동영상에서 추출한 이미지이기 때문에 연속성이 강해서 train set과 validation set을 의미있게 나누기 위해 데이터를 섞어 주었다.
역시 jupyter notebook을 통해 한번에 파일을 관리하였다.
import random
txt = open('/media/gopiz/extra/vision_project/darknet/custom/train2.txt','r')
f = open('/media/gopiz/extra/vision_project/darknet/custom/train_suffle.txt','w')
tmp = []
while True :
line = txt.readline()
if not line:
break
tmp.append(line)
random.shuffle(tmp)
for i in tmp :
f.write(i)
txt.close()
f.close()
train_suffle.txt를 확인해보면 순서가 섞여있는 것을 확인할 수 있다.
/media/gopiz/extra/vision_project/Yolo_mark/x64/Release/data/img2/001_abgr.jpg
/media/gopiz/extra/vision_project/Yolo_mark/x64/Release/data/img2/001_acqb.jpg
/media/gopiz/extra/vision_project/Yolo_mark/x64/Release/data/img2/001_acgr.jpg
/media/gopiz/extra/vision_project/Yolo_mark/x64/Release/data/img2/001_abqb.jpg
/media/gopiz/extra/vision_project/Yolo_mark/x64/Release/data/img2/001_aanh.jpg
/media/gopiz/extra/vision_project/Yolo_mark/x64/Release/data/img2/001_acur.jpg
/media/gopiz/extra/vision_project/Yolo_mark/x64/Release/data/img2/001_acge.jpg
/media/gopiz/extra/vision_project/Yolo_mark/x64/Release/data/img2/001_abes.jpg
이제 train set과 validation set으로 나눠보자.
count = 0
length = 2135 #total line
txt = open('/media/gopiz/extra/vision_project/darknet/custom/train_suffle.txt','r')
i = 0
f = open('/media/gopiz/extra/vision_project/darknet/custom/train.txt','w')
f2 = open('/media/gopiz/extra/vision_project/darknet/custom/validation.txt','w')
while True :
if i == 0 :
line = txt.readline()
if not line :
break
count +=1
if count < int(length/10)*2 :
f2.write(line)
else :
f.write(line)
txt.close()
f.close()
f2.close()
모든 작업이 끝났으면 train : validation이 8:2의 비율로 나눠진 것을 확인할 수 있다.
custom.names 파일 생성
yolo는 class의 index로 훈련을 하지만 index에 따른 class의 이름을 같이 표시해줄 수 있게 만들어 졌다. 그러므로 names파일을 넣어줘야 class의 이름을 확인할 수 있다. gedit명령어를 통해 custom.names파일을 생성한다.
Dough
Tomato
Onion
Pineapple
Mushroom
Sweet_potato
Wedge_potato
Garlic_chip
Black_olive
Bulgogi
Pepperoni
Bacon
Corn
Fire_chicken
SP_cube
이런식으로 본인의 데이터셋에 맞는 Class이름을 index순서대로 쭉 작성해주면 된다.
custom.data 파일 생성
gedit명령어를 통해 custom.data파일을 생성한다. data파일은 yolo 훈련의 좌표가 되는 파일이라고 볼 수 있다.
클래스의 갯수, train set 경로, validation set경로, names파일의 경로, weight파일이 출력될 경로를 입력하여 준다.
classes= 15
train = custom/train.txt
valid = custom/validation.txt
names = custom/custom.names
backup = backup/
Pretrain 모델 다운로드
darknet에서 제공하는 pretrain 모델을 이용하면 좀 더 빠르고 정확한 학습을 진행할 수 있다. 터미널에서 wget으로 가중치를 다운로드 받는다.
wget https://pjreddie.com/media/files/darknet53.conv.74
다운로드가 완료되었다면 본격적으로 훈련을 진행한다.
YOLO v3 훈련하기
모든 준비가 끝났다면 훈련 명령어를 통해 훈련을 진행해보자. 하지만 yolo는 훈련 진행중에 과정을 확인하기 힘드므로 log파일을 만들어 훈련시켜주는 것이 좋다. (AlexAB의 darknet의 경우 옵션으로 mAP를 지원한다.)

logfile을 만들면서 훈련시키기 위해 tee명령어를 이용하면 쉽게 logfile을 생성할 수 있다.
./darknet detector train custom/custom.data custom/custom_yolov3.cfg darknet53.conv.74 | tee backup/train.log
훈련이 진행되고 있다면 다른 terminal창에서 iteration마다 생성되는 loss값을 확인해보자.
grep "avg" backup/train.log

이 방법은 현재 loss가 어느 정도 인지 한눈에 파악하기 좋지만, 훈련과정이 어떻게 진행되는지는 역시 알기 힘들기 때문에 log파일을 이용하여 그래프를 그려 보면 loss값의 진행상황을 파악하고, 좋은 모델을 효과적으로 선택하는 방법을 찾을 수 있다.
jupyter notebook에서 matplotlib를 이용하면 그래프를 빌드 할 때마다 실시간으로 확인할 수 있다.
import sys
import matplotlib.pyplot as plt
from tqdm import tqdm
lines = []
for line in tqdm(open('/media/gopiz/extra/vision_project/darknet/backup/train.log')):
if "avg" in line:
lines.append(line)
iterations = []
avg_loss = []
line_cnt=len(lines)
for i in tqdm(range(line_cnt)):
lineParts = lines[i].split(',')
iterations.append(int(lineParts[0].split(':')[0]))
avg_loss.append(float(lineParts[1].split()[0]))
fig ,ax = plt.subplots(2,1 , figsize = (10,10))
#start = 0
start = 4999
for i in range(start, line_cnt, 1000):
ax[0].plot(iterations[i:i+1], avg_loss[i:i+1], 'r*-')
#print(iterations[i], avg_loss[i])
ax[0].text(iterations[i], avg_loss[i],str(iterations[i]))
ax[0].set_xlabel('Iteration Number')
ax[0].set_ylabel('Avg Loss')
ax[0].set_title('loss graph')
for i in range(line_cnt-3000,line_cnt,):
ax[1].plot(iterations[i:i+2], avg_loss[i:i+2], 'r.-')
ax[1].set_xlabel('Iteration Number')
ax[1].set_ylabel('Avg Loss')
ax[1].set_title('Recent 3000')
#fig.savefig('training_loss_plot.png', dpi=1000)
이제 그래프를 확인해 보자.
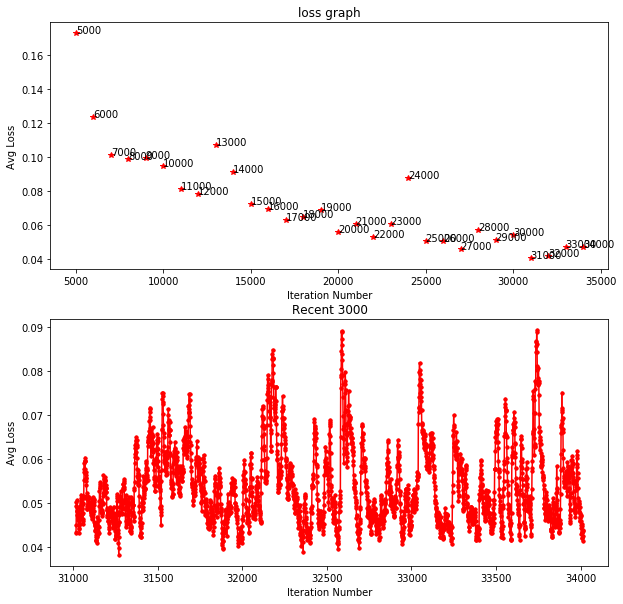
그래프를 확인해 보면 loss값이 충분히 낮아지면서 훈련이 잘 진행되고 있는것을 확인할 수 있다. 최근 3000iter를 보면 loss값이 smooth하지 않다는 것을 확인할 수 있다.
그래프에서 보면 31000iter의 loss값이 가장 낮으므로 출력되는 weight파일 중 31000iter의 weight를 선택하는 지표가 될 수 있다. *물론 loss가 낮다고 무조건 Accuracy가 높다는 뜻은 아니지만, 좋은 모델 선택의 하나의 지표가 될 수 있다는 것은 확실하다.
훈련 결과
야채 데이터를 훈련시킨 결과 피자 영상을 매우 잘 예측하는 것을 확인할 수 있다.

'Computer Vision > Object detection' 카테고리의 다른 글
| Object detection mAP 측정방법 (2) | 2020.12.18 |
|---|---|
| YOLO v4 , Opencv를 이용해서 간단한 위치판독기 만들기 (12) | 2020.05.20 |
| YOLO v4 custom데이터 훈련하기 (23) | 2020.05.19 |
| Ubuntu 18.04 에서 Yolo v4 설치하기 (11) | 2020.05.19 |
| Yolo v3 설치하기 (0) | 2020.04.17 |



